Model
Django框架功能齐全自带数据库操作功能,本文主要介绍Django的ORM框架
到目前为止,当我们的程序涉及到数据库相关操作时,我们一般都会这么搞:
- 创建数据库,设计表结构和字段
- 使用 MySQLdb 来连接数据库,并编写数据访问层代码
- 业务逻辑层去调用数据访问层执行数据库操作
ORM是什么?:(在django中,根据代码中的类自动生成数据库的表也叫–code first)
1 | ORM:Object Relational Mapping(关系对象映射) |
Django orm的优势:
Django的orm操作本质上会根据对接的数据库引擎,翻译成对应的sql语句;所有使用Django开发的项目无需关心程序底层使用的是MySQL、Oracle、sqlite….,如果数据库迁移,只需要更换Django的数据库引擎即可;
一、Django连接MySQL
1、创建数据库 (注意设置 数据的字符编码)
由于Django自带的orm是data_first类型的ORM,使用前必须先创建数据库
1 | create database wzc default character set utf8 collate utf8_general_ci; |
2、修改project中的settings.py文件中设置 连接 MySQL数据库(Django默认使用的是sqllite数据库)
1 | DATABASES = { |
扩展:查看orm操作执行的原生SQL语句
在project中的settings.py文件增加
1 | LOGGING = { |
3、修改project 中的initpy 文件设置 Django默认连接MySQL的方式
1 | import pymysql |
4、setings文件注册APP
1 | INSTALLED_APPS = [ |
5、models.py创建表
6、进行数据迁移
6.1、在winds cmd或者Linux shell的项目的manage.py目录下执行
1 | python manage.py makemigrations #根据app下的migrations目录中的记录,检测当前model层代码是否发生变化? |
扩展:修改表结构之后常见报错

这个报错:因为表创建之时,新增字段既没有设置默认值,也没有设置新增字段可为空,去对应原有数据导致;
2中解决方法:
1 | 1.设置新增字段可以为空 null=True |
7.设置pycharm可视化MySQL
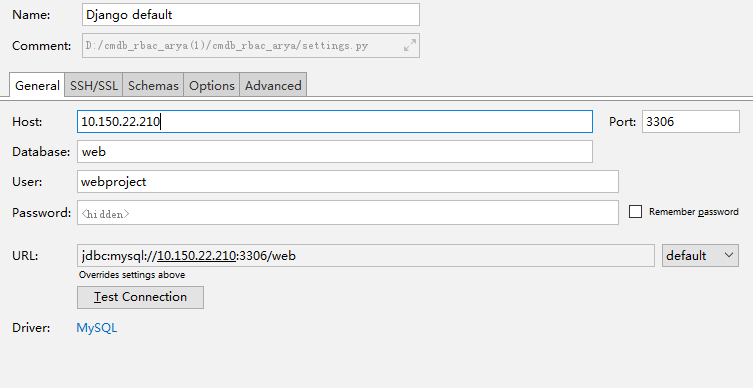
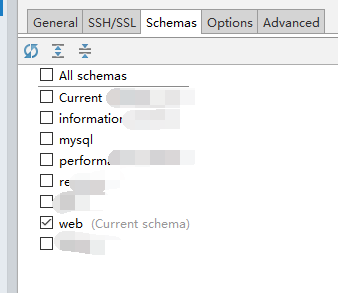
二、modles.py创建表
ORM字段介绍
Djan提供了很多字段类型,比如URL/Email/IP/ 但是mysql数据没有这些类型,这类型存储到数据库上本质是字符串数据类型,其主要目的是为了封装底层SQL语句;
1、字符串类(以下都是在数据库中本质都是字符串数据类型,此类字段只是在Django自带的admin中生效)
1 | name=models.CharField(max_length=32) |
1 | EmailField(CharField): |
扩展
models.CharField 对应的是MySQL的varchar数据类型
char 和 varchar的区别 :
char和varchar的共同点是存储数据的长度,不能 超过max_length限制,
不同点是varchar根据数据实际长度存储,char按指定max_length()存储数据;所有前者更节省硬盘空间;
2、时间字段
models.DateTimeField(null=True)
date=models.DateField()
3、数字字段
(max_digits=30,decimal_places=10)总长度30小数位 10位)
1 | 数字: |
4、枚举字段
1 | choice=( |
扩展
在数据库存储枚举类型,比外键有什么优势?
1、无需连表查询性能低,省硬盘空间(选项不固定时用外键)
2、在modle文件里不能动态增加(选项一成不变用Django的choice)
其他字段
1 | db_index = True 表示设置索引 |
字段参数介绍
1.数据库级别生效
字段
1 | AutoField(Field) |
参数
1 | null 数据库中字段是否可以为空 |
2、Django admin级别生效
针对 dango_admin生效的参数(正则匹配)(使用Django admin就需要关心以下参数!!)
1 | blanke (是否为空) |
连表结构
- 一对多:models.ForeignKey(其他表)
- 多对多:models.ManyToManyField(其他表)
- 一对一:models.OneToOneField(其他表)
1 | 应用场景: |
字段以及参数
1 | ForeignKey(ForeignObject) # ForeignObject(RelatedField) |
三、ORM单表操作
1、基本操作
1 | # 增 |
2、进阶操作(了不起的双下划线)
利用双下划线将字段和对应的操作连接起来
1 | # 获取个数 |
3、高级操作
1 | # extra |
4、其他操作
1 | ################################################################## |
4、连表操作(了不起的双下划线)
利用双下划线和 _set 将表之间的操作连接起来
表结构实例
1 | class UserProfile(models.Model): |
一对一操作
1 | user_info_obj = models.UserInfo.objects.filter(id=1).first() |
一对多
1 | 类似一对一 |
多对多操作
1 | user_info_obj = models.UserInfo.objects.get(name=u'武沛齐') |