Scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下
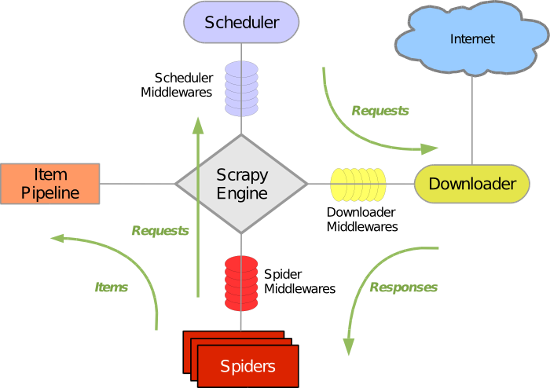
Scrapy主要包括了以下组件:
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
一、安装
Linux
1 | pip3 install scrapy |
Windows
1 | pip3 install wheel |
二、基本使用
基本命令
1 | 1. scrapy startproject 项目名称 |
项目结构以及爬虫应用简介
1 | project_name/ |
注意:一般创建爬虫文件时,以网站域名命名
pipelines.py
专门用来保存数据的,其中三个方法会经常使用。
open_spider(self, spider):当爬虫被打开的时候执行
process_item(self, item, spider):当爬虫中有item传过来的时候被调用
close_spider(self,spider):当爬虫关闭的时候会被调用
要激活并使用pipelines的话,记得在settings.py中将ITEM_PIPELINES设置
1 | ITEM_PIPELINES = { |
items.py
专门用来定义模型。建议使用,以后就不要在spider文件中使用字典
1 | name = scrapy.Field() |
spiders文件夹下创建的爬虫.py
1 | response是一个 scrapy.http.response.html.HtmlResponse 对象,可以执行 xpath 和css 语法来提取数据 |
例:
1 | import scrapy |
保存json数据
JsonItemExporter和JsonLinesItemExporter
保存json数据类型的时候。可以使用这两个类,让操作变得简单
1.JsonItemExporter:这个是每次把数据添加到内存,最后统一写入磁盘中。好处是,储存的数据是一个满足json规则的数据,坏处是如果数据量比较大,那么比较耗内存
1 | from scrapy.exporters import sonItemExporter |
2.JsonLinesItemExporter这个是每次调用export_item()的时候就把这个item储存到硬盘中。坏处是每一个字典是一行,整个文件不是一个满足json格式的文件,好处是每次处理数据的时候就直接存储到了硬盘,这样不会耗内存,数据也比较安全,而且不需要写start和finish
1 | from scrapy.exporters import JsonLinesItemExporter |
两种方式,都是byte写入,所以,文件打开要用byte类型打开
CrawlSpider
在之前我们解析完整个页面后获取下一页的url,然后重新发送一个请求。
有时候我们想要这么做,只要满足某个条件的URL,都给我爬取,那么这个时候我们就可以通过CrawlSpider 来帮我们完成了。CrawlSpider继承自Spider只不过是在之前的基础上增加了新的功能,可以定义爬取url的规则,以后scrapy碰到满足条件的url都进行爬取,而不需要自己手动yield scrapy.Request
创建CrawlSpider爬虫
之前创建爬虫的方式是通过scrapy genspider [爬虫名] [域名]的方式创建的。如果想要创建CrawlSpider爬虫,那么应该通过以下的命令创建
1 | scrapy genspider -t crawl [爬虫名] [域名] |
-t crawl表示以crawl为模板来创建爬虫
scrapy genspider -l可以查看所有的模板
LinkExtractors链接提取器
使用LinkExtractors可以不要程序员自己提取想要的url,然后发送请求,这些工作都可以交给LinkExtractors,他会在所有爬的页面中找到满足规则的url,实现自动的爬取,以下对LinkExtractors类做一个简单的介绍
1 | class scrapy.linkextractors.LinkExtractor( |
主要参数讲解:
- allow:允许的url。所有满足这个正则表达式的url都会被提取。
- deny:禁止的url。所有满足这个正则表达式的url都不会被提取。
- allow_domains:允许的域名。只有在这个里面指定的域名的url才会被提取。
- deny_domains:禁止的域名。所有在这个里面指定的域名的url都不会被提取。
- restrict_xpaths:严格的xpath。和allow共同过滤链接。
Rule规则类
定义爬虫的规则类。以下对这个类做一个简单的介绍:
1 | class scrapy.spiders.Rule( |
主要参数讲解:
- link_extractor:一个
LinkExtractor对象,用于定义爬取规则。 - callback:满足这个规则的url,应该要执行哪个回调函数。因为
CrawlSpider使用了parse作为回调函数,因此不要覆盖parse作为回调函数自己的回调函数。什么情况下使用:如果这个url对应的页面,只是为了获取更多的url,并不需要里面的数据,那么可以不指定callback。 - follow:指定根据该规则从response中提取的链接是否需要跟进。什么情况下使用:如果在爬取页面的时候,需要将满足当前条件的url在进行跟进,那么就设置为True,否则为False
- process_links:从link_extractor中获取到链接后会传递给这个函数,用来过滤不需要爬取的链接。
例:
1 | from scrapy.linkextractors import LinkExtractor |
Scrapy Shell
我们想要在爬虫中使用xpath、beautifulsoup、正则表达式、css选择器等来提取想要的数据,但是引文scrapy是一个比较中的框架,每次运行起来都要等待一段时间,因此要去验证我们写的提取规则是否正确,是一个比较麻烦的事情,因此scrapy提供了一个shell,用来方便的测试规则,当然也不仅仅局限于这个一个功能。
打开Scrapy Shell
打开cmd终端,进入到Scrapy项目所在的目录,然后进入到scrapy框架所在的虚拟环境中,输入命令scrapy shell [链接]。就会进入到scrapy的shell环境中。在这个环境中,你可以跟在爬虫的parse方法中一样使用了。
Scrapy Shell笔记
- 可以方便我们做一些数据提取的测试代码。
- 如果想要执行scrapy命令,那么毫无疑问,肯定是要先进入到 scrapy所在的环境中。
- 如果想要读取某个项目的配置信息,那么应该先进入到这个项目中,再执行
scrapy shell命令。
Request和Response对象
Request对象
Request对象在我们写爬虫,爬取一面的数据需要重新发送一个请求的时候调用。这个类需要传递一些参数,其中比较常用的参数有:
- url:这个request对象发送请求的url。
- callback:在下载器下载完相应的数据后执行的回调函数。
- method:请求的方法。默认为
GET方法,可以设置为其他方法。 - headers:请求头,对于一些固定的设置,放在
settings.py中指定就可以了。对于那些非固定的,可以在发送请求的时候指定。 - meta:比较常用。用于在不同的请求之间传递数据用的。
- encoding:编码。默认的为
utf-8,使用默认的就可以了。 - dont_filter:表示不由调度器过滤。在执行多次重复的请求的时候用得比较多。
- errback:在发生错误的时候执行的函数。
Response对象
Response对象一般是由scrapy给你自动构建的。因此开发者不需要关心如何创建Response对象,而是如何使用它。Response对象有很多属性,可以用来提取数据的。主要有以下属性:
- meta:从其他请求传过来的
meta属性,可以用来保持多个请求之间的数据连接。 - encoding:返回当前字符串编码和解码的格式。
- text:将返回来的数据作为
unicode字符串返回。 - body:将返回的数据作为
bytes字符串返回。 - xpath:xpath选择器。
- css:css选择器。
发送POST请求
有时候我们想要在请求数据的时候发送post请求,那么这时候需要使用 Request的子类和FormRequest 来实现。如果想要在爬虫一开始的时候就发送 POST 请求,那么需要在爬虫类中重写 start_requests(self) 方法,并且不再调用 start_urls 里的url。
模拟登录
案例一:模拟登录豆瓣网,更改个性签名
- 想要发送post请求,那么推荐使用
scrapy.FormRequest方法。可以方便的指定表单数据。 - 如果想在爬虫一开始的时候就发送post请求,那么应该重写
start_requests方法。在这个方法中,发送post请求。
1 | # -*- coding: utf-8 -*- |
下载文件和图片
Scrapy为下载item中包含的文件(比如在爬取到产品时,同时也想保存对应的图片)提供了一个可重用的item pipelines。这些 pipeline有些共同的方法和结构(我们称之为 media pipeline)。一般来说会使用 Files pipeline或者 Image Pipeline。
为什么要选择使用 scrapy 内置的下载文件的方法
- 避免重新下载最近已经下载过的数据。
- 可以方便的指定文件存储的路径。
- 可以将下载的图片转换成通用的格式。比如png或jpg。
- 可以方便的生成缩略图。
- 可以方便的检测图片的宽和高,确保他们满足最小限制。
- 异步下载,效率非常高。
下载文件的 Files Pipeline
当使用Files Pipeline 下载文件的时候,按照以下步骤来完成:
- 定义好一个
Items,然后在这个item中定义两个属性,分别为file_urls以及files。file_urls是用来存储需要下载的图片的url链接,需要给一个列表。 - 当文件下载完成后,会把文件下载的相关信息存储到
item的files属性中。比如下载路径、下载的url和文件的校验码等。 - 在配置文件
settings.py中配置FILES_STORE,这个配置是用来设置文件下载下来的路径。设置为一个有效的文件夹,用来存储下载的图片。 否则管道将保持禁用状态,即使你在ITEM_PIPELINES设置中添加了它。 - 启动
pipeline:在ITEM_PIPELINES中设置scrapy.pipelines.files.FilesPipeline:1。
下载图片的 Image Pipeline
当使用Image Pipeline下载文件的时候,按照以下步骤来完成:
- 定义好一个Item,然后在这个 Item 中定义两个属性,分别为
image_urls以及images。image_urls是用来存储需要下载的图片的url链接,需要给一个列表。 - 当文件下载完成后,会把文件下载的相关信息存储到
item的images属性中。比如下载路径、下载的url和文件的校验码等。 - 在配置文件
settings.py中配置IMAGES_STORE,这个配置是用来设置文件下载下来的路径。设置为一个有效的文件夹,用来存储下载的图片。 否则管道将保持禁用状态,即使你在ITEM_PIPELINES设置中添加了它。 - 启动
pipeline:在ITEM_PIPELINES中设置scrapy.pipelines.images.ImagesPipeline:1。
Downloader Middlewares(下载中间件)
下载器中间件是引擎和下载器之间通信的中间件,在这个中间件中我们可以设置代理,更换请求头等来达到反反爬虫的目的。要写下载器中间件,可以再下载器中实现两个方法,一个是process_request(self,request,spider),这个方法是在请求发送之前会执行,还有一个是process_response(self,request,response,spider),这个方法是数据下载到引擎之前执行。
process_request(self,request,spider)
这个方法是下载器在发送之前会执行的。一般可以在这个里面设置随机代理ip等
- 参数
request:发送请求的request对象
spider:发送请求的spider对象
- 返回值
返回None:如果返回None,Scrapy将继续处理该request,执行其他中间件中的相应方法,直到合适的下载器处理函数被调用。
返回Response:Scrapy将不会调用其他任何的
process_request将直接返回这个response对象,已经激活的中间件的process_response()方法则会在每个response返回时被调用。返回Request:不再使用之前的request对象去下载数据,而是根据现在返回的request对象返回数据。
如果这个方法中抛出了异常,则会调用
process_exception方法
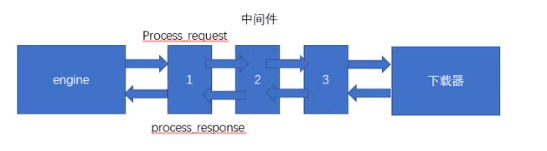
process_response(self,request,response,spider)
这个是下载器下载的数据到引擎中间会执行的方法
- 参数:
- request:request对象
- response:被处理的response对象
- spider:spider对象
- 返回值:
- 返回Response对象:会将这个新的response对象传给其他中间件,最终传给爬虫。
- 返回Request对象:下载器链被切断,返回的request会重新被下载器调度下载。
- 如果抛出一个异常,那么调用request的errback方法,如果没有指定这个方法,那么会抛出一个异常。
随机请求头中间件
爬虫在频繁访问一个页面的时候,这个请求头如果一直保持一致,那么很容易被服务器发现,从而禁止掉这个请求头的访问。因此我们要在访问这个页面之前随机的更改请求头,这样才可以减小爬虫被抓的几率。随机更改请求头,可以在下载中间件中实现,在请求发送给服务器之前,随机的选择一个请求头,这样就可以避免总是使用一个请求头了,代码如下:
1 | class UserAgentDownloadMiddleware(object): |
user-agent列表网站 http://useragentstring.com/pages/useragentstring.php?name=All
ip代理池中间件
购买代理:
在以下代理商中购买代理:
- 芝麻代理
- 太阳代理
- 快代理
- 讯代理
- 蚂蚁代理