冒泡排序
冒泡排序的思想: 每次比较两个相邻的元素, 如果他们的顺序错误就把他们交换位置
比如有五个数: 12, 35, 99, 18, 76, 从大到小排序, 对相邻的两位进行比较
- 第一趟:
- 第一次比较: 35, 12, 99, 18, 76
- 第二次比较: 35, 99, 12, 18, 76
- 第三次比较: 35, 99, 18, 12, 76
- 第四次比较: 35, 99, 18, 76, 12
经过第一趟比较后, 五个数中最小的数已经在最后面了, 接下来只比较前四个数, 依次类推
- 第二趟
99, 35, 76, 18, 12 - 第三趟
99, 76, 35, 18, 12 - 第四趟
99, 76, 35, 18, 12
比较完成
冒泡排序原理: 每一趟只能将一个数归位, 如果有n个数进行排序,只需将n-1个数归位, 也就是说要进行n-1趟操作(已经归位的数不用再比较)
时间复杂度:O(n²)
1 | def my_sort(num): |
快速排序
快速排序使用分治法(Divide and conquer)策略来把一个序列(list)分为两个子序列(sub-lists),从数列中挑出一个元素,称为 “基准”(pivot);
重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置
时间复杂度O(nlog₂n)
1 | def quicksort(li): |
插入排序
插入排序:选定元素,分别与列表中的元素比较,小的在左边,大的在右边
1.从第一个元素开始,该元素可以认为已经被排序;
2.取出下一个元素,在已经排序的元素序列中从后向前扫描;
3.如果该元素(已排序)大于新元素,将该元素移到下一位置;
4.重复步骤3,直到找到已排序的元素小于或者等于新元素的位置;
5.将新元素插入到该位置后;
重复步骤2~5。
1 | def insertsort(li): |
选择排序
选择排序就是要首先选定一个元素认为为最小的,之后比较其他,如果小于之前的,换更换列表所在位置。
时间复杂度:O(n²)
1 | def changesort(li): |
归并排序
归并排序:采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并
时间复杂度:O(nlog₂n)
归并排序也就是将列表中的元素分成两个长度为n/2的子序列,进行比较,之后合在一起
1 | def merge_sort(list1):#merge_sort是按照len(list1)//2分开,知道分成两两比较大小 |
堆排序
堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆;或者每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆。
大顶堆:arr[i] >= arr[2i+1] && arr[i] >= arr[2i+2] 父节点i的左子节点在位置(2i+1); 父节点i的右子节点在位置(2i+2)
小顶堆:arr[i] <= arr[2i+1] && arr[i] <= arr[2i+2]
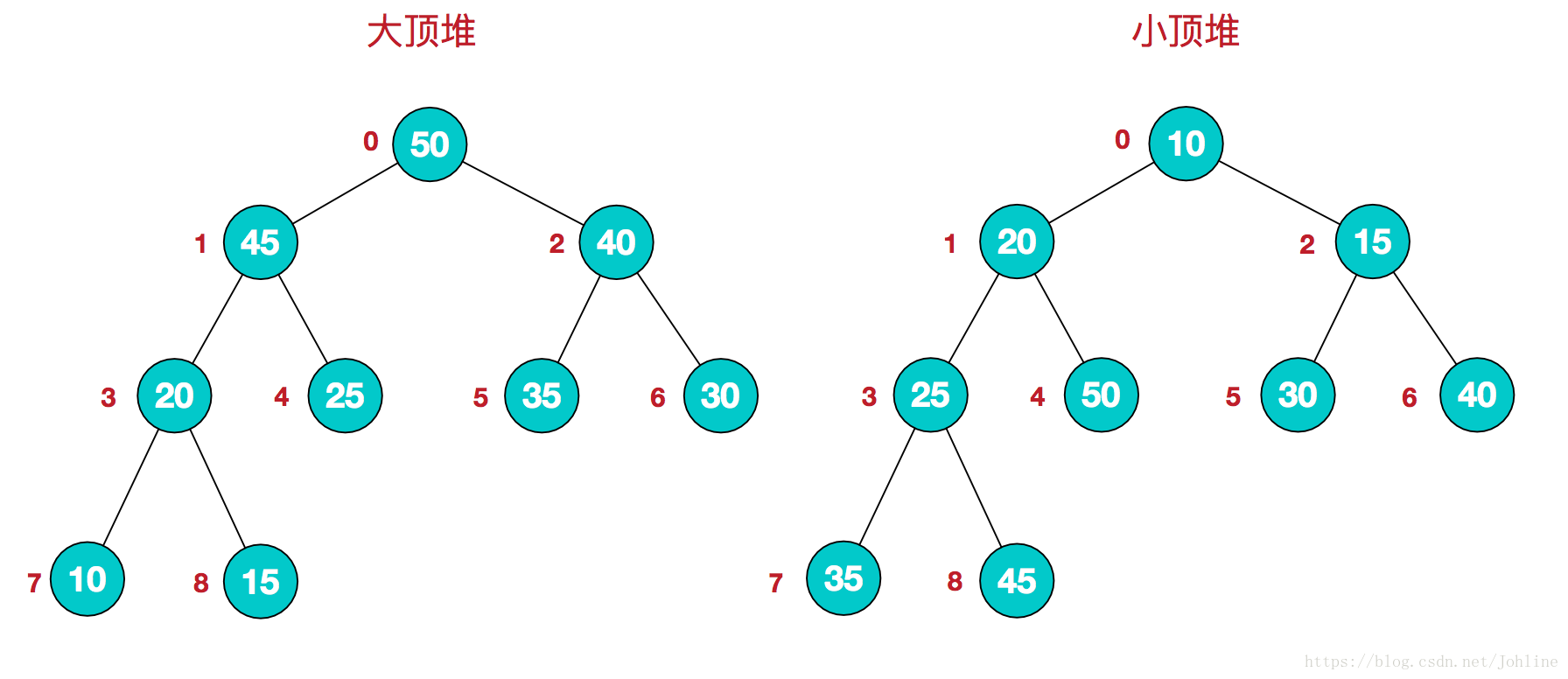
堆排序:
- 将无序列表构建最大堆,根节点为最大元素
- 将堆顶元素与末尾元素进行交换,使末尾元素最大。然后继续调整堆,再将堆顶元素与末尾元素交换,得到第二大元素。如此反复进行交换、重建、交换。

1 | def heap_sort(hlist): |
时间复杂度O(nlog₂n),不稳定
希尔排序
希尔排序将元素先平分,gap=len(list1)//2,按照gap去比较,一次//2,直到gap为1,
例如:gap=4,0-4,1-5,2-6,3-7,4-8,5-9去比较大小,若小于前面的,则交换位置。
时间复杂度:O(n)
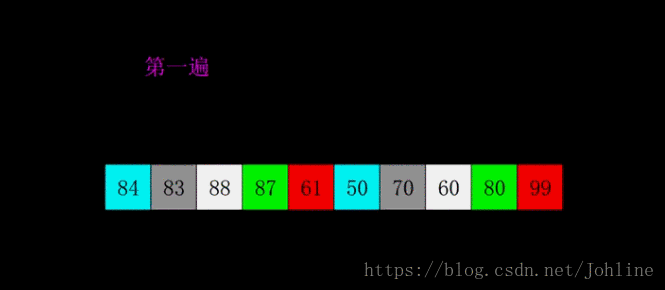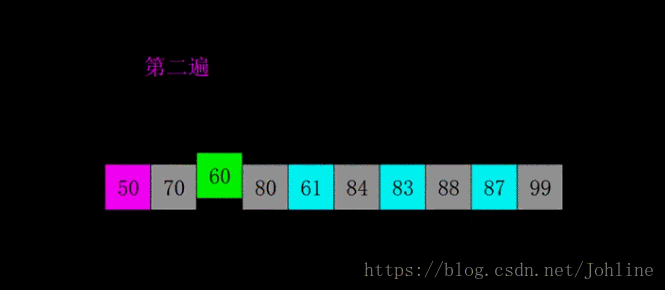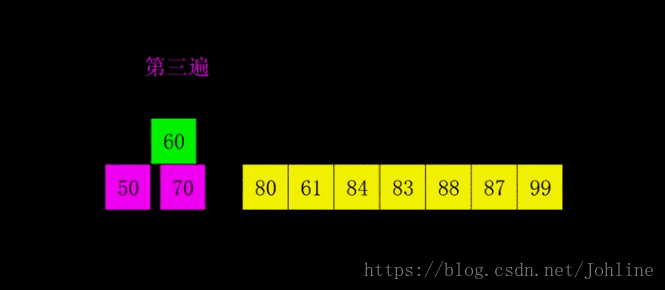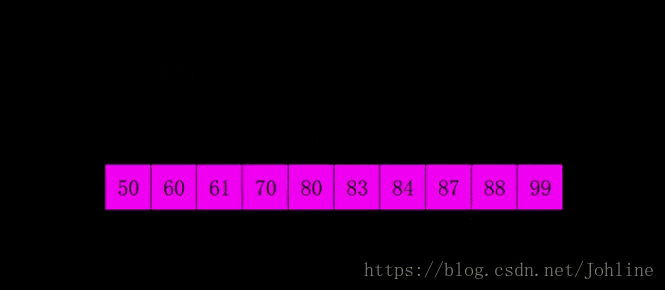
1 | def Shell_sort(list1): |